Getting Data, Part One
Much of this blog will be focused on NHL data, as I mentioned in the opening post. There are two main sources for data about NHL hockey, from Hockey-Reference.com and from the R package nhlscrapr. This post we’ll focus on getting score data from Hockey-Reference from the start of the NHL to the present day.
A typical season’s results on Hockey-Reference has this url format (http://www.hockey-reference.com/leagues/NHL_2016_games.html), and looks like this:
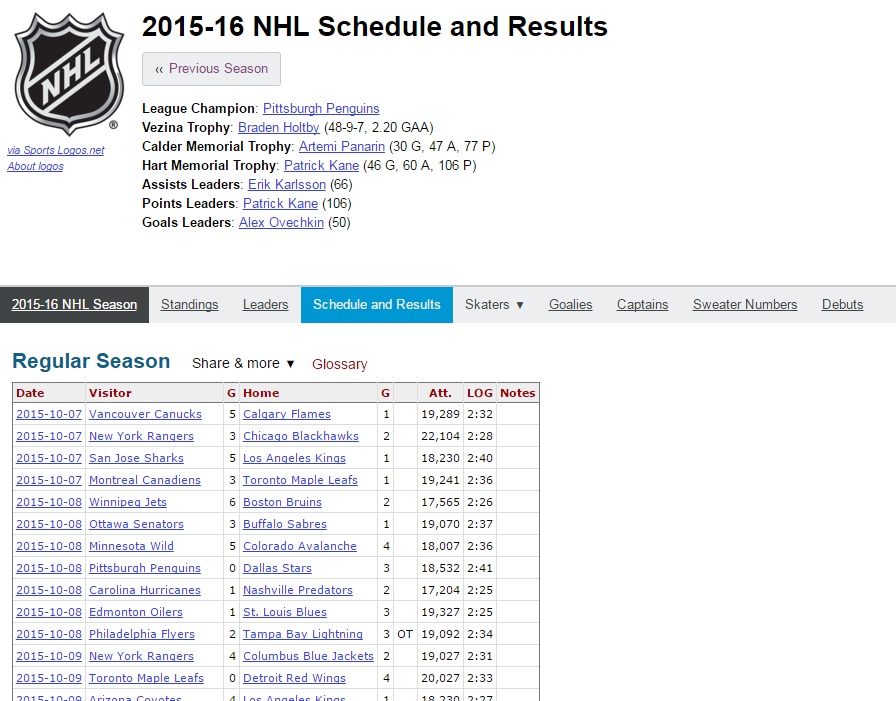
Copy-pasting this to import would be tedious, particuarly with 100 years of NHL hockey approaching. That’s too much data to handle manually, so we’ll write some scraping code to get it for us.
For this, we’ll use some of R’s built in tools, as well as the XML library. This library will allow us to automatically parse the HTML files, which we’ll save to a .csv file for later.
We can read the page (with the XML library loaded) with the readHTMLTable function. This will find all the table chunks, of which there are typically 2 on these pages, and store them. An alternate way to do this would be to read the whole HTML file with htmlParse, then extract the tables, but this one step is easier.
library(XML)
tables <- readHTMLTable("http://www.hockey-reference.com/leagues/NHL_2016_games.html")
unlist(lapply(tables, function(t) dim(t)[1]))## games games_playoffs
## 1230 91We have two tables here, namely tables['games'] and tables['games_playoff']. This contains the data we wanted:
head(tables[["games"]])## Date Visitor G Home G Att. LOG Notes
## 1 2015-10-07 Vancouver Canucks 5 Calgary Flames 1 19,289 2:32
## 2 2015-10-07 New York Rangers 3 Chicago Blackhawks 2 22,104 2:28
## 3 2015-10-07 San Jose Sharks 5 Los Angeles Kings 1 18,230 2:40
## 4 2015-10-07 Montreal Canadiens 3 Toronto Maple Leafs 1 19,241 2:36
## 5 2015-10-08 Winnipeg Jets 6 Boston Bruins 2 17,565 2:26
## 6 2015-10-08 Ottawa Senators 3 Buffalo Sabres 1 19,070 2:37We can save this to a .csv file very simply with write.csv(tables['games'], file = '2016games.csv'). But that only gets us one season.
We’ll set it up in a for-loop, to be able to get a few more seasons at once, say from 2010-2015. I’ve broken the regular season and playoffs apart before saving, for easy referece. I’ve also added Sys.sleep(20), as it’s polite not to slam servers with requests but to let other traffic through.
for (i in c(2010:2015)) {
readHTMLTable(paste0("http://www.hockey-reference.com/leagues/NHL_", i,
"_games.html"))
regular <- tables[["games"]]
playoff <- tables[["games_playoffs"]]
message(" Saving...", "\r", appendLF = FALSE)
write.csv(regular, file = paste0("./", i - 1, i, ".csv"))
write.csv(playoff, file = paste0("./", i - 1, i, "Playoffs.csv"))
Sys.sleep(20)
}A few things need to be taken care of here. What if we aren’t currently in the playoffs of the most recent year available (currently, the 2017 season). That portion will create an empty file, so let’s escape that.
if (!is.null(playoff)) {write.csv(playoff, file = paste0("./", i - 1, i, "Playoffs.csv"))}
As well, what if we try collect the season data for 2005? Give it a shot here. There was no hockey that year, due to the lockout, so we need to skip 2005 in the for loop.
if (i == 2005) {next}
Now, what if the website is down, or something else happens weird while parsing data? We should wrap our readHTMLTable in a tryCatch, and our parsing and saving in a null checker.
I’ll also add some messages to the code, as we can wait for quite some time between starting the loop and getting all of the data out. By using the message("Message", "\r", appendLF = FALSE) format, each message will be on the same line as the next message. the final message for ‘waiting’ will return a new line afterwards.
Putting this all together:
start <- 2010
end <- 2015
wait <- 20
for (i in c(start:end)) {
# No season in 2004-2005. Don't try process that year.
if (i == 2005) {
message("Skipping 2004-2005 season (lockout)")
next
}
message(paste0("Working on NHL season: ", i - 1, "-", i), "\r", appendLF = FALSE)
message(" Downloading...", "\r", appendLF = FALSE)
tables <- tryCatch({
readHTMLTable(paste0("http://www.hockey-reference.com/leagues/NHL_",
i, "_games.html"))
}, warning = function(w) {
message(w)
}, error = function(e) {
message(e)
## In case of download or other error, explicitly pass nothing.
tables <- NULL
})
if (!is.null(tables)) {
## In case of download error, don't process
message(" Processing...", "\r", appendLF = FALSE)
regular <- tables[["games"]]
playoff <- tables[["games_playoffs"]]
message(" Saving...", "\r", appendLF = FALSE)
write.csv(regular, file = paste0("./", i - 1, i, ".csv"))
if (!is.null(playoff)) {
write.csv(playoff, file = paste0("./", i - 1, i, "Playoffs.csv"))
}
}
message(paste0("Waiting ", wait, " seconds."))
Sys.sleep(wait)
}We’ve almost got our scraper ready, but it would be nice to host it all in a simple function call. Robust functions have input checks, and this will need a few.
a) We want start to be less than end, b) We dont want to start before the 1917-1918 season, c) We don’t want to start in the future (past 2016-2017), d) We can’t end past the future (again, 2016-2017), e) We can’t start and/or end in 2005 (no season).
Wrapping it all up:
getAndSaveNHLGames <- function(start = 1918, end = 2017, wait = 30) {
if (!require(XML)) {
return(FALSE)
}
if (start > end) {
message("Start must be less than end. Reversing values.")
tmp <- start
start <- end
end <- tmp
rm(tmp)
}
if (start < 1918) {
message("NHL started in 1917-1918. Collecting data from there forwards.")
start <- 1918
}
if (start > 2017) {
message("Can's start collecting data past next season. Collecting final season.")
start <- 2017
end <- 2017
}
if (end > 2017) {
message("Can't collect past this season. Collecting up to there.")
end <- 2017
}
if (start == 2005 && end == 2005) {
message("Can't collect 2004-2005. No season due to lockout. Not collecting any data.")
return(FALSE)
}
if (start == 2005) {
message("Can't collect 2004-2005. No season due to lockout. Collecting from 2005-2006 to there.")
start <- 2006
}
if (end == 2005) {
message("Can't collect 2004-2005. No season due to lockout. Collecting to 2003-2004 to there.")
end <- 2004
}
for (i in c(start:end)) {
# No season in 2004-2005. Don't try process that year.
if (i == 2005) {
message("Skipping 2004-2005 season (lockout)")
next
}
message(paste0("Working on NHL season: ", i - 1, "-", i), "\r", appendLF = FALSE)
message(" Downloading...", "\r", appendLF = FALSE)
tables <- tryCatch({
readHTMLTable(paste0("http://www.hockey-reference.com/leagues/NHL_",
i, "_games.html"))
}, warning = function(w) {
message(w)
}, error = function(e) {
message(e)
## In case of download error, don't pass nothing.
tables <- NULL
})
if (!is.null(tables)) {
## In case of download error, don't process
message(" Processing...", "\r", appendLF = FALSE)
regular <- tables[["games"]]
playoff <- tables[["games_playoffs"]]
message(" Saving...", "\r", appendLF = FALSE)
write.csv(regular, file = paste0("./", i - 1, i, ".csv"))
if (!is.null(playoff)) {
write.csv(playoff, file = paste0("./", i - 1, i, "Playoffs.csv"))
}
}
message(paste0("Waiting ", wait, " seconds."))
Sys.sleep(wait)
}
return(TRUE)
}Woah, I hear you saying that you might want to see the WHA scores too, since the leagues merged in the late ’70s? Sure!
getAndSaveWHAGames <- function(start = 1973, end = 1979, wait = 30) {
if (!require(XML)) {
return(FALSE)
}
if (start > end) {
message("Start must be less than end. Reversing values.")
tmp <- start
start <- end
end <- tmp
rm(tmp)
}
if (start < 1973) {
message("WHA started in 1972-1973. Collecting data from there forwards.")
start <- 1973
}
if (start > 1979) {
message("WHA ended in 1978-1979. Collecting final season.")
start <- 1979
end <- 1979
}
if (end > 1979) {
message("WHA ended in 1978-1979. Collecting up to there.")
end <- 1979
}
for (i in c(start:end)) {
message(paste0("Working on WHA season: ", i - 1, "-", i), "\r", appendLF = FALSE)
message(" Downloading...", "\r", appendLF = FALSE)
tables <- tryCatch({
readHTMLTable(paste0("http://www.hockey-reference.com/leagues/WHA_",
i, "_games.html"))
}, warning = function(w) {
message(w)
}, error = function(e) {
message(e)
## In case of download error, don't pass nothing.
tables <- NULL
})
if (!is.null(tables)) {
## In case of download error, don't process
message(" Processing...", "\r", appendLF = FALSE)
regular <- tables[["games"]]
playoff <- tables[["games_playoffs"]]
message(" Saving...", "\r", appendLF = FALSE)
write.csv(regular, file = paste0("./wha", i - 1, i, ".csv"))
write.csv(playoff, file = paste0("./wha", i - 1, i, "Playoffs.csv"))
}
message(paste0(" Waiting ", wait, " seconds."))
Sys.sleep(wait)
}
}So now after you call getAndSaveNHLGames() and getAndSaveWHAGames() and wait a while, you’ve got a full set of score data for NHL and WHA games. Cool! I’ll look later at cleaning some of this data for easy use.